
``Ethiopic'' is the term most familiar to the western world for the primary writing system of
Eritrea and Ethiopia. Other terms that have been used for the script in the west have been
``Abyssinian'', ``Ethiopian'' and ``Abyssinic''. In Eritrea and Ethiopia the writing system is
known affectionately as ``Ge'ez'', ``Fidel'', and ``Fidelat'' and the foreign names may never
be heard in ones lifetime. The terms may be used interchangably here to refer to the
extended writing system. This includes all additional characters added to classic Ge'ez
 for tgrNa, amarNa,
guragiNa and other languages, numbers, punctuation, and musical notes.
for tgrNa, amarNa,
guragiNa and other languages, numbers, punctuation, and musical notes.

The Cursive Syllabary of Emperor Menelik
Legends of Ethiopic Computerization
Notes on Ethiopic Localization.
The Oromo Syllabary of Shayk Bakri Sapalo
Ethiopic Support in Babel
Getting Started On UTF-8 (constructing)
Info On SERA-97
From He To Po A projects coordination page for the Internet
The Ethiopic Unicode Domain in PostScript
Java And Its Potential For Fidel
History of the Fidel and Gif of Fidel Evolution
Additional History by Yohannes Negase-Sium
Ethiopic Numbers and the latest algorithm
alt.ethiopic.text Discussions at UseNet
JIS Pages
JUNET Pages
Junet Injera Recipe for Mule
SERA Pages
Library of Ethiopian Texts
Ethiopian Literary Corner
by Michal Jerabek (Visit The
Bookshelf Page!)
The Indiana Fidel FTP Archive @ftp.geez.org/
PC and MS Windows
EthiO Systems!! MS Windows fonts and the EthTeX package.
Feedel fonts for all MS Windows Applications.
Goha an Add-On for WordPerfect 5.1
The Ethiopian Computers & Software Homepage
WINCALIS Info
Sabaean Fonts Grandparent of Fidel
Unix and X Windows
Admas Development Page for F10N
X11 Fonts for Fidel and The X11 Fonts Initiative
Ethiopic Emacs Version 2.3 is Here!
Fidel Banner v0.17 Unix Like ``Banner'' for Fidel
sera2any v0.25 Latin to Ethiopic
Converter for JIS, JUNET, Unicode, etc.
Now with RTF support for Agafari, ALXEthiopian, Feedel, and Washra Fonts!!
sera2latex SERA To LaTeX Converter
sera2ps v2.3.8 Latin to Ethiopic PostScript Converter
Ethiopic-Viewer v0.48a A file viewer having growing pains...
A descriptive paper for the coding system is now available
A paper on the principal of limited Fidel sets and prioritized encoding is now available.
These are merits of SERA as an encoding system for transliteration
and should not compared to, or confused with, coding systems that
deal with ordering and assigning Fidel code space.
SERA Web may be read in Latin without complication,
or ideally with Mule and the
W3 browser
which will automatically convert SERA text into Fidel between <sera> and
</sera> markups.
Additional On-Web info concerning SERA :-
System for Ethiopic Representation in ASCII The FAQ
Haddis was
developed at EthiO Systems,
it is described as ``The minimum required characters for adequate use as Ato Haddis
Alemayehu's book Fiker Eske Mekabir.'' The Haddis prioritized Fidel is encoded in the
limited Extened ASCII range of 32 - 255. Most ASCII punctuations are available but
Latin letters are not. Haddis is one very good solution for the classic problem of
working with Ethiopic's large character set in single byte code spaces.
JIS is the acronym for Japanese Industrial
Standard. Encoding of Fidel has been applied in the private use
region beginning at Kuten [91,1] and follows a proposed Unicode
ordering. Most Unix operating systems, IBM's OS/2, and special versions
of MS Windows and DOS do use JIS (and a variant called Shift-JIS). JIS
provides a means to import Fidel into multibyte operating systems and
applications while Unicode replacements are being developed.
JUNET is the anacronym for Japanese Unix Network
used for Email and Newgroup exchanges in Japan.
MULE is a valuable JUNET interprettor. Fidel is
encoded in the 4-byte range following Admas modulo class ordering.
The only known use of the Ethiopic JUNET range is in Mule's display
buffer. Since Mule converts bilingual SERA (for languages using
Roman and Fidel scripts) natively, JUNET encoding is not generally
required for Fidel documents.
SERA is the acronym for (The) System for Ethiopic
Representation in ASCII. SERA does NOT assign code
points (addresses) to Fidel characters. SERA is strictly a transliteration
encoding system for 7-bit information interchange of Fidel. However, SERA
may be applied in a hypothetical 3-byte encoding system
(not recommended). Or in a variable width encoding system using both
1 and 2 byte characters. SERA files will always consume less memory
space than 2-byte systems. The primary merits of SERA are:-
SERA Unabbridged
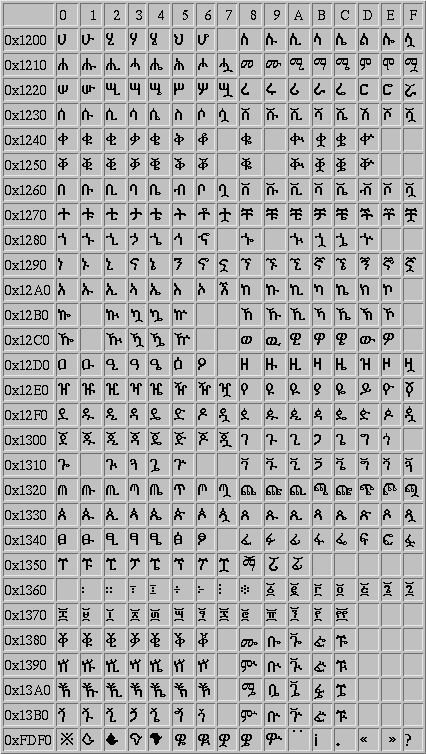
Table SERA Fidel
The SERA User's Guide (Has 1997 Revisions and Additions)Unicode and ISO-10646 are compatible 2 and 4-byte character
coding systems for the world's writing systems. Plan-9, AIX, and
Linux are operating systems already using Unicode. The Unicode
standard is in release 1.0 and inclusion of Fidel is expected in a
release after standard 2.0. A time frame for the Unicode standard with
Fidel is unknown. Most software implementation issues
for Fidel (L18N, IM & I/O) may be resolved with the proposed coding
standards while waiting for Unicode and ISO's final resolution.
 Return to ACG Homepage
Return to ACG Homepage{kind=link}
{kind=link}