Notes on Ethiopic Localization
There are 87 Ethiopian and 8 Eritrean languages in the collective regions
where Ethiopic text is in use. Orthographic practices are numerous; often
language specific, influenced by neighboring, external, and even extinct
languages. This document does not attempt to address specific orthographic
practices nor does it address localization with respect to input methods,
national language support or other GUI issues but is intended to provide
information on and example of general text formatting issues common to
computer operating and word processing systems.
The task of describing formatting practices in Ethiopia is one on par with
describing the shapes of clouds in Ethiopia. Like clouds Ethiopic formatting
is rather hard to pin down for study and careful description. Before one could
finish describing the shape it would invariably change before you.
Fortunately, and like clouds as well, formats come from all places and in a
wide range of shapes which people are willing to accept with little aversion to
difference. But there
is commonality among these clouds over Ethiopia that we can consider. The
point here is to keep in mind that at this time there are no standard
conventions for formatting text in Ethiopia but rather a plethora of defacto
standards for modern practices coexisting with fairly well known rules from
traditional practices.
Click here to downlaod a zip archive of these pages (long file names used -get Winzip to extract!)
Click here to view this page with Unicode addresses in place of Ethiopic images.
To send comments, corrections, and suggestions for the development of this
document send email to yacob@ethiopic.org.
Formatting Ethiopic Text
Ethiopic Wordspace
The Ethiopic wordspace character,  (U+1361),
was a device originally used to
minimize the space between words on a line while keeping the words discernible.
In this way allowing scribes to maximize the use of available space on their
labor intensively produced writing material, Brana. ``Hulet Neteb'' was still in
strong use during the first half of the present century. The Addis Zemen
newspaper stopped using the Hulet Neteb in 1942 which is a good reference
point to mark the decline of the character. Hulet Neteb is oddly used more in
hand written practices today than in modern typesetting, though it remains
vital to the later.
(U+1361),
was a device originally used to
minimize the space between words on a line while keeping the words discernible.
In this way allowing scribes to maximize the use of available space on their
labor intensively produced writing material, Brana. ``Hulet Neteb'' was still in
strong use during the first half of the present century. The Addis Zemen
newspaper stopped using the Hulet Neteb in 1942 which is a good reference
point to mark the decline of the character. Hulet Neteb is oddly used more in
hand written practices today than in modern typesetting, though it remains
vital to the later.
Rules of Hulet Neteb:
- Is used between words in lieu of a blank space.
- Is properly centered between words though in some publishing practices
and in hand written practices will adhere to the end of the word it
follows.
- Does not follow or precede other punctuation.
- Usually does not follow but may precede an Ethiopic number
(this is general and not strict).
- Does not start a new line when a line breaks, it will be the last
character on the preceding line.
- Is not used to delimit hours, minutes and seconds in time -some
typist may do this when their font does not have a colon, or when
changing fonts to use a colon would be laborious.
- Otherwise may use ``normal'' rubber spacing rules on either side in
fully justified text.
- Should be recognized as having both space and punctuation character
classes.
In Eritrean-Tigrigna the Hulet Neteb (or ``Kelete Netbi'') is used in place
of  (U+1363) in Ethiopian practices
and thus takes on a different syntactic meaning. The use as a list or numeric
separator is not known to the present author.
(U+1363) in Ethiopian practices
and thus takes on a different syntactic meaning. The use as a list or numeric
separator is not known to the present author.
Default Question Mark
This is really more of an IM issue; In Eritrean-Tigrigna,
 (U+1367), is the
preferred question mark character. U+1367 is otherwise unknown in
Ethiopia where an Ethiopic-ized U+007F is a must.
(U+1367), is the
preferred question mark character. U+1367 is otherwise unknown in
Ethiopia where an Ethiopic-ized U+007F is a must.
Other Punctuation
In keeping with Ethiopic wordspace no additional space is inserted before or
after Ethiopic punctuation. In modern practices a single word space will be
added after the punctuation. It should also be noted that while an Ethiopic
paragraph separator, 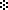 (U+1368), is
identified in the Unicode standard for Ethiopic, it is not used in modern
practices.
(U+1368), is
identified in the Unicode standard for Ethiopic, it is not used in modern
practices.
Ethiopicized Punctuation
A characteristic trait of Ethiopic writing is that the weight of the
text is heavier than for most other scripts. The apparent ``extra
weight'' should also be applied to borrowed text elements from other
scripts. This included western numerals and punctuation. Doing so
gives the text and a natural and continuous visual flow. Not doing so
becomes visually confusing. It is the prevalent practice in professional
computer fonts to add this extra weight.
Additionally, and for the same esthetic benefit, the rules of curvature
may be borrowed from Ethiopic elements and grafted onto the borrowed foreign
symbols. Recommended examples of this practice are demonstrated in the
Monotype and SIL Premier Ethiopic fonts which enjoy widespread use in
government and private houses in Ethiopia.
Ethiopic Hyphenation
Ethiopic follows similar rules to English where a word may be split over
two lines at a syllable. Since all Ethiopic word elements are syllables
the splitting point is considered arbitrary and no hyphenation character
is used.
The lack of a hyphenation character might sound alarming, many Ethiopian
words are in fact compound words so practices could easily lead to ambiguity.
This indeed would be so and the practice likely never would have evolved
were it not for use of the Ethiopic Wordspace (U+1361) to clearly mark
word boundaries. It is only recently since the decline of Ethiopic wordspace
that Ethiopic hyphenation has lead to uncertain interpretation of text.
Readers knowing the context of a passage have little or no cognitive exercise
in reforming a broken compound word. This area is primarily a concern to
text and word processing tools.
Abbreviated Text
Abbreviation rules vary only slightly from those in American-English
practices. For example Ethiopia's capital city, Addis Ababa, would
be abbreviated in American-English as ``A.A.'' while in Ethiopia
``U+12A0/U+12A0'' would
be the most common form. Fullstop (U+002E) is commonly used in place of
forward slash (U+002F) as in
``U+12A0.U+12A0'' -take care to note that unlike American-English, when fullstop
is used no fullstop is applied after the terminal character of the
abbreviation.
Abbreviations are very common and fairly standard in office practices,
a list of the most common can be found here.
Formatting Lists
Lists in Ethiopic text are separated by Ethiopic comma, (U+1363), followed by ASCII space. Ethiopic semicolon and
colon may also be found in use as a list separator. This is a common resort
of typists when the Ethiopic comma is not available in an Ethiopic font. It
is also indicative of the overlapping or interchangeable roles of the
punctuation as is often their perception.
Ordered Lists
Ordered list are given in Ethiopic text using the first form of an Ethiopic
syllable followed generally by a "/" or ".". In example:
U+1200/
U+1208/
U+1210/
:
After the first cycle additional cycles are given by incrementing though
the syllabary
U+1200U+1200/
U+1200U+1208/
U+1200U+1210/
:
and for the 3rd cycle:
U+1208U+1200/
U+1208U+1208/
U+1208U+1210/
:
and so on.
Numbers are less often used in lists though they do play a more important
role in numbering chapters and sections in books and for labeling verses
in Ethiopian Bibles.
Bullet Lists
The standard shapes used as bullets (circles, squares and triangles) are
accepted and used in bullet lists in Ethiopia. The Ethiopic paragraph
separator, and variant
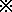 (U+1368),
should be available to the composer as a bullet item as well.
(U+1368),
should be available to the composer as a bullet item as well.
Dialogue Lists
Ethiopic preface colon is most commonly found in interviews at
the end of the presenters name before the dialogue passage is given:
- Time:- What was your analysis of the situation then?
- Davis:-
- - - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - -
- - - - - - - - - - - - - - - - - - - - - - - - - -
Preface colon may also be used to terminate an item in an ordered
list as per:
U+1200U+1366
U+1208U+1366
U+1210U+1366
:
Otherwise the preface colon is found to take on many of the roles filled
by the western colon.
Formatting Numerals
Both Ethiopic and Western numerals are in use today. Though the Ethiopic
has long since been retired to a reserved use primarily for calendar dates and
demarcation of sections in literature. While Western numerals are used
everywhere else following western practices.
As noted previously Ethiopic numerals may serve as their own word boundaries
when Hulet Neteb is in use. Like Roman numerals their Ethiopic counterparts
have bars above and below that are commonly rendered as a continuous line in
a numeric sequence.
Also noteworthy is that an Ethiopic ordinal system analogous to
1st, 2nd, etc. is common where for either Ethiopic
or western numerals the superscript 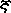 (U+129B) is used in Amharic and
(U+129B) is used in Amharic and
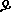 (U+12ED) in Tigrigna.
(U+12ED) in Tigrigna.
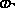 (U+129BU+12CD) becomes the superscript in Amharic when the sense is
definite (as in ``the first''). The same superscripts are used with
fractions.
(U+129BU+12CD) becomes the superscript in Amharic when the sense is
definite (as in ``the first''). The same superscripts are used with
fractions.
Delimiters
Ethiopic numerals sequences do not use commas or decimal points. Commas are
used to delimit groups of three digits in western numbers and full stop is
used as a decimal separator. Also true with currency, the roles of comma
and full stop are often found to reverse.
Counting
The Ethiopic numerals are a set of twenty characters. The first 9 are
the digits 1-9 and next 10 are the numbers 10-100 the last is the number
10,000 though in recent decades it has fallen into misuse as 1,000.
Online
algorithms offer an explanation for how the numbers increment.
Negative Ethiopic numerals are not used. The format for negative western
numerals is simply -123.
Formatting Currency
There is no Ethiopic currency symbol for Ethiopia's monetary unit the Birr
(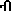
 (U+1265U+122D)). Rather,
the dollar symbol is borrowed and prefixed without a space before the value.
The preferred dollar glyph uses the two unbroken vertical lines crossing the
uppercase ``S''. Negative currency notation appends the minus sign before the
dollar without additional space -$123
(U+1265U+122D)). Rather,
the dollar symbol is borrowed and prefixed without a space before the value.
The preferred dollar glyph uses the two unbroken vertical lines crossing the
uppercase ``S''. Negative currency notation appends the minus sign before the
dollar without additional space -$123
No more than two places are given after the decimal. Values of less than
one Birr may still be formatted as a whole value where the leading zero may
or may not be present before the decimal. As in the west the alternate
formatting without the decimal is not uncommon where a superscripted
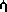 (U+1233) is used in lieu of a cents sign (i.e. ¢).
(U+1233) is used in lieu of a cents sign (i.e. ¢).
Formatting Dates and Times
There are a mirade of possibilities for the formatting of dates and time
in Ethiopia. The basis for date formatting comes from the Ethiopian Calendar
which is a variant of the better known Julian calendar. In brief the epoch of
the Ethiopian calendar is roughly 7 years and 8 months after that of the
Gregorian. The calendar has 13 months, there are 12 months of 30 days and a
13th month of 5 days. There is a leap year every four years in which the 13th
month will gain a 6th day. The current year is 1991 which is a leap year.
ANSI C computer code for Ethiopian and Gregorian calendar conversions, with
Ethiopic formatting utilities, may be found here
here.
- Abbreviated day of week and month names are rarely practiced. Under extreme
space limitations the days of the week and month names will be simply
truncated to fit the available space while the truncated name remains
uniquely identifiable. This means day of week names may be given by
a minimum of 1 letter (the first) and months given by the first two
letters in Amharic. Tigrigna truncations require two letters for the
day of week name.
- Ethiopic numerals are not used in digital clocks for hours, minutes, seconds. English numerals are used.
- Ethiopic numerals are used for dates of the month and
years. Realized DATE YEAR formations with respect to numerals types as per:
ETHIOPIC-DIGIT-DATE ETHIOPIC-DIGITS-YEAR
ENGLISH-DIGIT-DATE ETHIOPIC-DIGITS-YEAR
ENGLISH-DIGIT-DATE ENGLISH-DIGITS-YEAR
- Ethiopian clocks are 6 hours back. Meaning ``12 Noon'' would be ``6 AM'' and ``6 AM'' is the zero hour. Users would likely want the option to toggle between both.
- Each day of the month has a proper name under Orthodox Christian practices.
- There is no direct analog to AM and PM in Ethiopian practices. Generally the reference is given is given in the expression of a phrase. To give a binary division around the meridian (remember this is at the 6th hour of the day) the best terms would be
U1320U+12CBU+1275
for AM and
U+12A8U+1230U+12D3U+1275
for PM.
- There are direct analogs to BC (U+12D3/U+12D3) and AD (U+12D/U+121D) in the Ethiopic calendar system. They are used much more often in date formats than in Western practices.
- Comma does not follow the date in date formatting. Rather the word for ``day''
(U+1240U+1290 in Amharic or
U+1218U+12D3U+120DU+1272 in Tigrigna)
is used as shown in the template:
DAY, MONTH DATE U+1240U+1290 HOUR:MIN:SEC YEAR AD
Applying the above we can demonstrate a few of the possible accepted examples of a formatted date:
| U+12A5U+1211U+12F5U+1363 U+1325U+1245U+121DU+1275 5 U+1240U+1295 01:13:46 U+1372U+1371U+137AU+1369 U+12D3.U+121D |
A long format date using a 24-hour clock. |
| U+12A5U+1211U+12F5U+1363 U+1325U+1245U+121DU+1275 U+136D U+1240U+1295 01:13:46 U+1372U+1371U+137AU+1369 U+12D3.U+121D |
The same but the date of the week is an Ethiopic digit. |
| U+12A5U+1211U+12F5U+1363 U+1325U+1245U+121DU+1275 5 U+1240U+1295 01:13:46 1991 U+12D3/U+121D |
Our date now uses western numerals and . is
replaced by / as user preference has changed. |
| U+12A5U+1211U+12F5U+1363 U+1325U+1245U+121DU+1275 5 U+1240U+1295 1:13:46 U+1320U+12CBU+1275 U+1372U+1371U+137AU+1369 U+12D3/U+121D |
Using a 12 hour clock the hour becomes ambiguous so the
meridian field is used. |
| U+12A5U+1211U+12F5U+1363 U+1325U+1245U+121DU+1275 5 U+1240U+1295 07:13:46 AM 1991 U+12D3/U+121D |
The same hour under the Western reference system. This will
likely be desirable to Ethiopians working outside of Ethiopia and
with foreign agencies within Ethiopia. Though the clock is a 24
hour clock, ``AM'' is added in English to clarify the Western
reference. |
| U+12A5U+1211U+12F5 U+1325U+1245U+121DU+1275 5 01:13:46 1991 |
The minimalist format under horizontal space limitations. Any
of the fields now absent were always independently optional. |
Collation
Ugghhh... This is tedious. At least 4 basic matricies are in use,
labiovelars may be added to the matricies in at least 3 different
ways, then things get language specific.
Stick with the Unicode layout for now.
Character Classes
In text processing it is essential to be aware of the character class
one is operating on. The table below shows the most basic divisions
within the Ethiopic syllabary as defined in the Unicode standard.
| [U+1200-135A] | Syllable |
|---|
| [U+1369-137C] | Ethiopic Digits |
|---|
| [U+1361-1368] | Punctuation |
|---|
| U+1361 | Space |
|---|
|
In linguistic processing it is a necessity to be able to detect and reset
the syllabic form of an Ethiopic syllable. Fortunately the modulo class (with
a modulo division of 8) of the syllable's Unicode address readily reveals
syllabic form of the character. It is also essential in both text and
linguistic processing to detect the number of siblings a syllable may have.
The following table shows this with respect to Unicode address space.
Syllable Families:
| Having 7 Forms |
[U+1200-U+1206]
[U+12C8-U+12CE]
[U+12D0-U+12D6]
[U+12E8-U+12EE]
[U+1340-U+1346]
[U+1318-U+131E]
|
|---|
| Having 8 Forms |
Everything in [U+1200-U+1357]
not having 7 or 12 forms :-)
|
|---|
| Having 12 Forms |
[U+1240-U+124D]
[U+1250-U+125D]
[U+1280-U+128D]
[U+12A8-U+12B5]
[U+12B8-U+12C5]
[U+1308-U+1315]
|
|---|
| Having 1 Form? |
The characters in [U+1358-135A] are very rarely occurring
and do not find 20th century use. It is uncertain if they
are best treated as a ligature or a 13th syllabic form of
their base class.
|
|---|
|
Other Classes
Classes have also be constructed from the linguistic values of the
written syllables. In many Ethiopian languages a syllabic set will
duplicate the phonemes of another set, or two forms within a set may
share a phoneme. It is useful in linguistic processing and IM to be aware
of this. Such occurrences are language sensitive and will be addressed in
this document in a future revision.
These papers
on regular expressions for Ethiopic also addresses Ethiopic character
classes.